Knowledge Distillation
Why we need Knowledge Distillation
The requirements of an AI model vary extensively between training and production environments. Knowledge Distillation helps us bridge the gap by enabling us to create models that perform well for their specific purpose.
Training
The model has to be able to grasp complex relationships and structures in the data.
In the training phase, having the maximum amount of data possible and using the largest model possible enables us to fully capture the distribution and complexities of the data.
Production
The model has to be able to provide inference quickly, at a low computational cost.
In production, when the model is deployed to many users, having high-quality outputs that are generated fast and with low cost is only possible with a small model.
| Environment | Size | Speed | Complexity |
|---|---|---|---|
| Training | Large | Can be slow | High |
| Production | Small | Needs to be fast | Low |
You can see that these two phases of an AI model's lifespan have almost contradicting requirements. This is where knowledge distillation comes in handy.
Knowledge Distillation
A technique that enables us to transfer knowledge from a larger model to a smaller one
Something important to keep in mind is, Knowledge Distillation's main purpose isn't to speed up training. It's to help a smaller model grasp complexities and relationships in the data that it might not have picked up on otherwise due to its limited size.
How it works
For this example, let's assume that we are training a model to recognize digits from the MNIST dataset. It's a dataset of images of handwritten digits from 0-9. The model has to correctly classify this data.
Looking at how the MNIST dataset is structured, we can see that it consists of images of numbers and a label for what that number is supposed to be.

We gain high accuracy by using an ensemble of models. It's a technique where we use many classification models to classify the data and then average the predictions from them to gain a final output prediction.
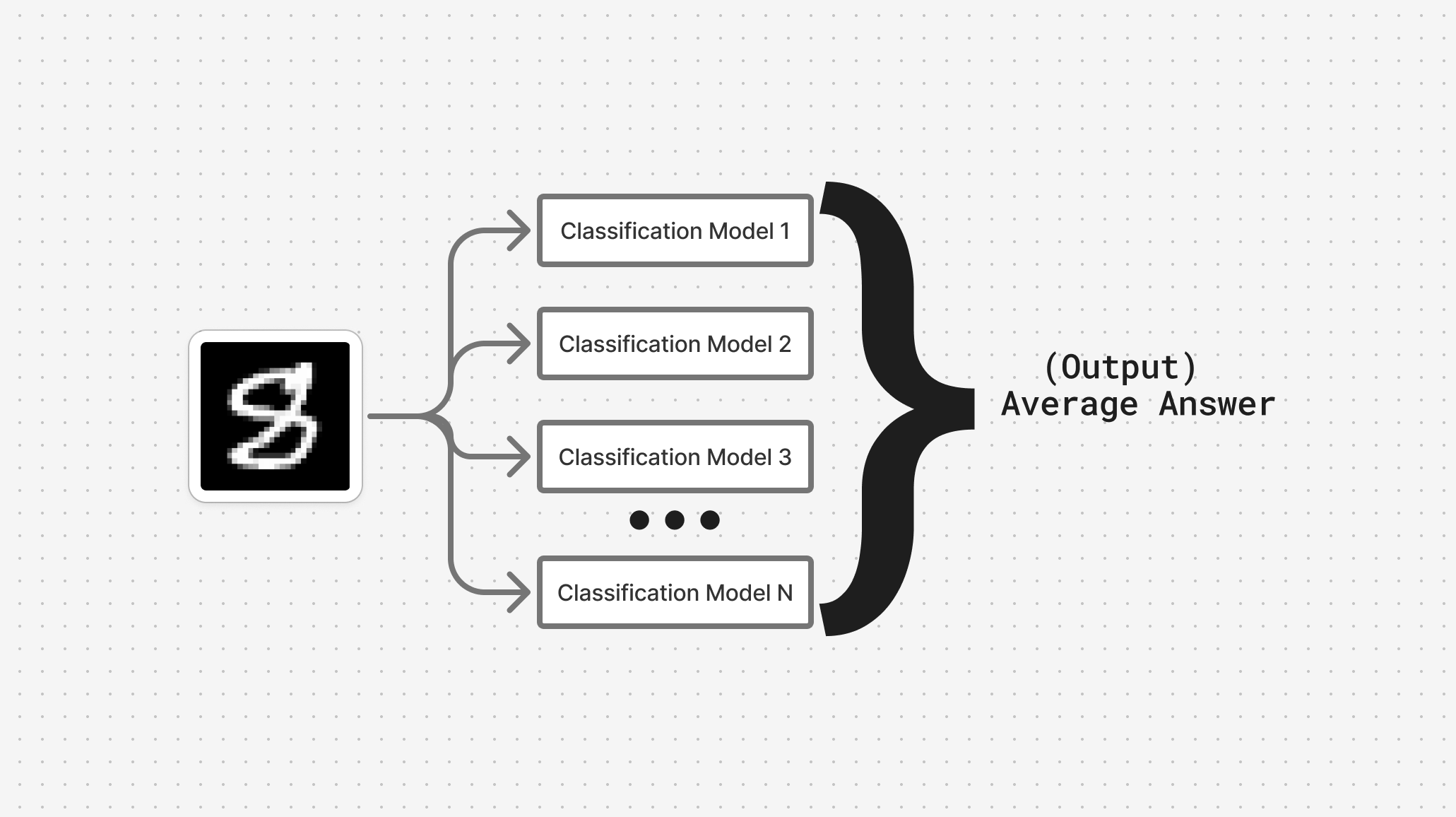
Now that we have high accuracy, the problem becomes, how do we reduce the size of this model for production environments?
We do this by training a smaller model on the soft labels produced by this ensemble's prediction instead of the original data.
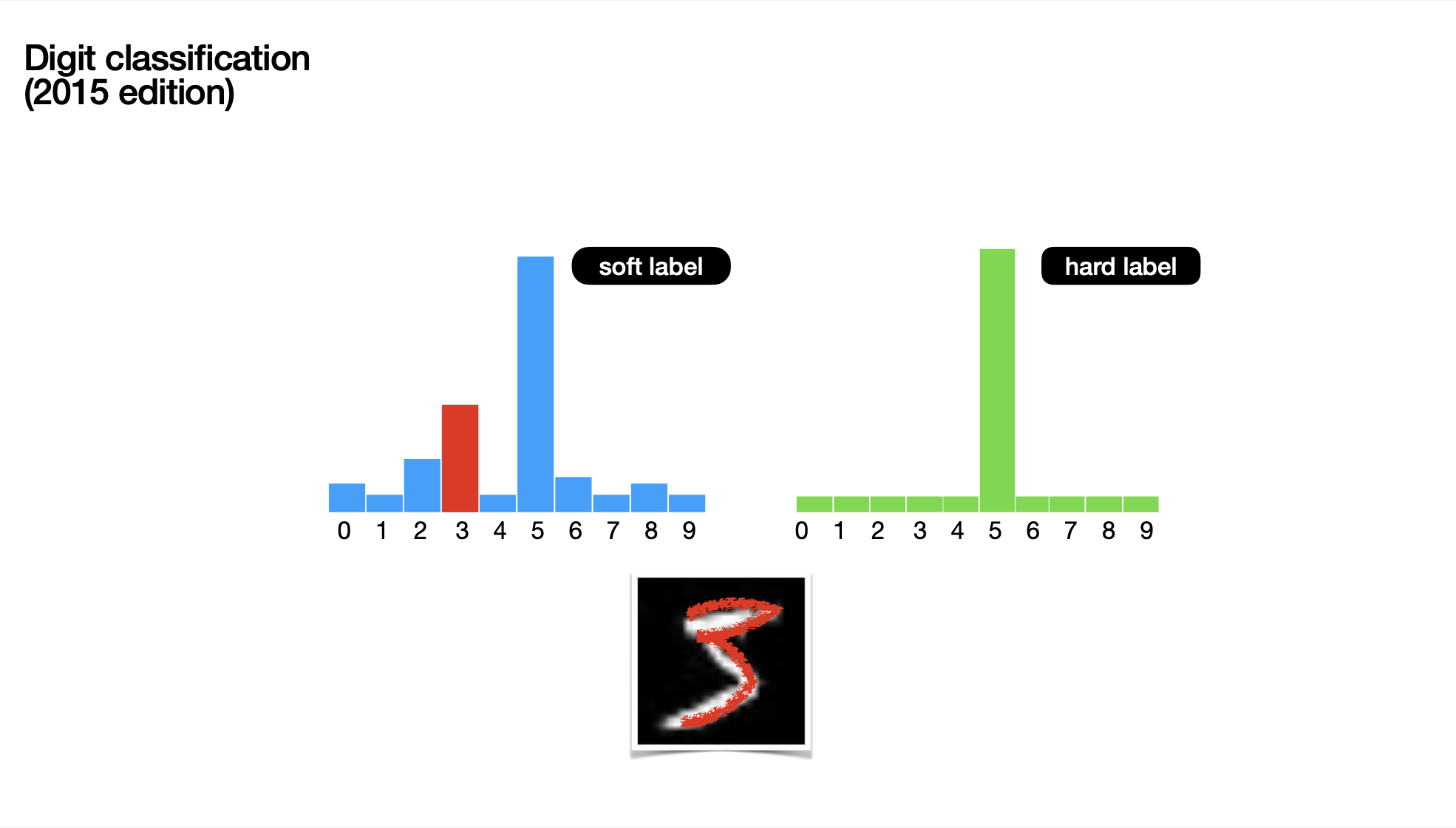
Apart from the correct digit, it also contains some extra, valuable information called 'dark knowledge'. This dark knowledge makes it easier for smaller models to *capture latent patterns* in the data that they might have missed otherwise due to their small parameter count.
This dark knowledge can be thought of as the larger model spoon-feeding the smaller model with information on how to correctly identify the images

As you can see from the image above, it's hard to tell if the image is a 3 or a 5.
*This disparity isn't captured in the hard label, which only contains the correct label, but the soft label very clearly shows that the second-highest probability is the number 3.*
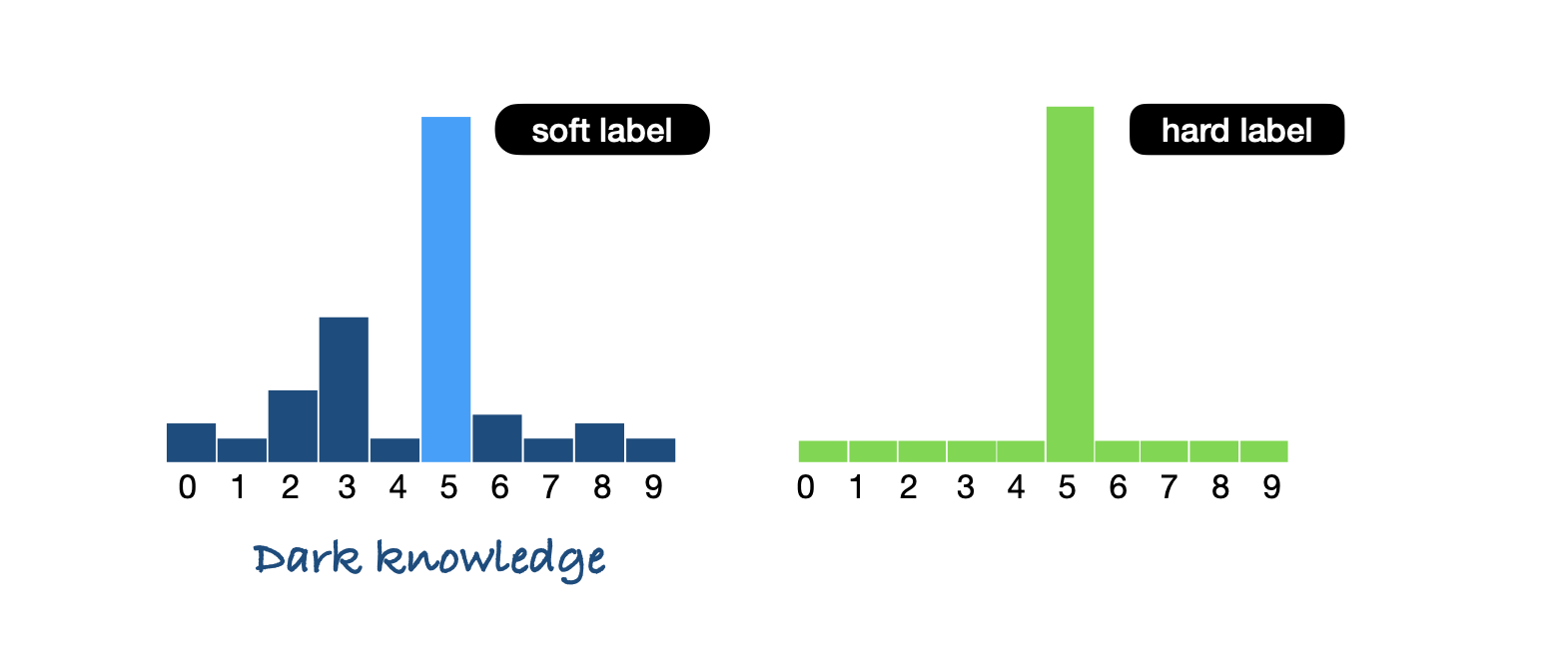
This enables the smaller models to be trained on very high-quality data that's designed to help them capture complexities with a smaller parameter count.
Context
Knowledge distillation is definitely not a new technology, originally conceived as far back as the early 2000s.
- It was used to enable fast, secure, and on-device speech transcription for voice assistants on edge devices
- It was used in object and scene detection technologies on smartphones and cameras
More recently, the 'modern' version of knowledge distillation came out in 2015 with the paper "Distilling the Knowledge in a Neural Network". It enables companies to make models that are smaller and smarter; enabling a more dense understanding of information.
When releasing models, companies usually put out several tiers of models.
Meta

Instead of training each model separately on all of the data, they train their largest, most powerful model, the Llama 4 Behemoth, first.
This model is then used as a teacher to distill information & train the two smaller models, Maverick and Scout.
These models are our best yet thanks to distillation from Llama 4 Behemoth
Google
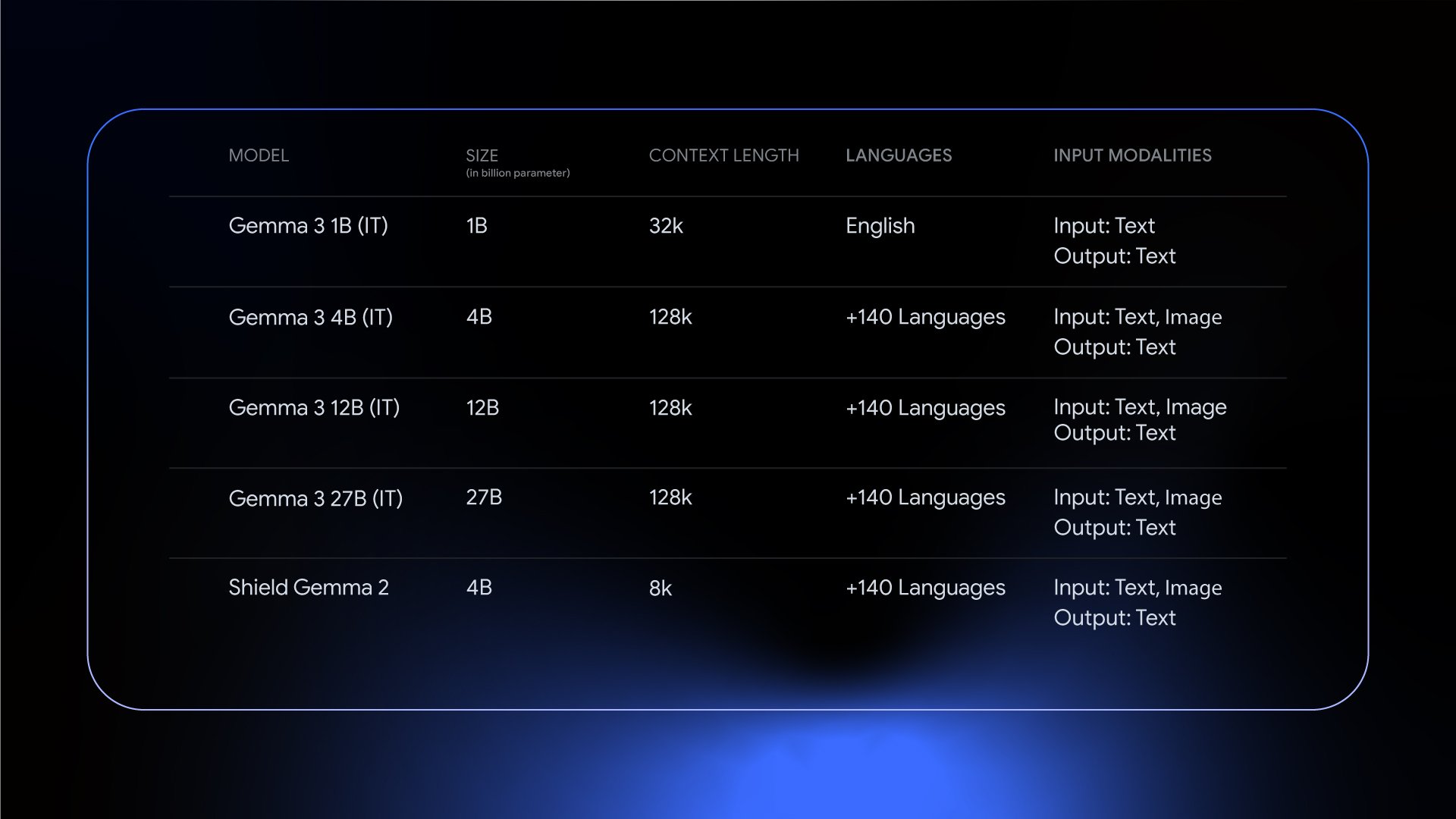
Google similarly uses Distillation to train their entire suite of open-source Gemma models, training them using their bigger, proprietary Gemini Line of Models.